One of the most widely use of assembly language is in writing
shellcode. If you new to this subject, try playing with assembly a bit.
Prerequisites: x86 Assembly language(Strictly Recommended).
2. C programming language.
Caution:The shellcodes can be used in most exploits without a problem.However, these codes may cause serious damage to your computer and should therefor only be used against TEST systems that have NO network connectivity! Imagine what happens if you run the backdoor on you system and forget about it ?
What is shellcode?
The shellcode is literally a "code" that returns a remote (or local) shell when executed. Shellcode can be seen as a list of instructions that has been developed in a manner that allows it to be injected in an application during runtime.The term “shellcode” (or “shell code”) derives from the fact that in many cases, malicious users utilize code that provides them with either shell access to a remote computer on which they do not possess an account or, alternatively, access to a shell with higher privileges on a computer on which they do have an account. In the optimal case, such a shell might provide root- or administrator-level access to a vulnerable system.
Understanding shellcode and eventually writing your own is, for many reasons, an essential skill. First and foremost, in order to determine that a vulnerability is indeed exploitable, you must first exploit it. Second, software vendors will often release a notice of a vulnerability but not provide an exploit. In these cases you may have to write your own shellcode if you want to create an exploit in order to test the bug on your own systems. Unfortunately, for many hackers the shellcode story stops at copying and pasting bytes. These hackers are just scratching the surface of what’s possible.Custom shellcode gives you absolute control over the exploited program. Perhaps you want your shellcode to add an admin account to /etc/passwd or to automatically remove lines from log files. Once you know how to write your own shellcode, your exploits are limited only by your imagination. In addition, writing shellcode develops assembly language skills and employs a number of hacking techniques worth knowing.
Understanding System Calls: As we have already discussed,System calls are APIs for the interface between user space and kernel space.We write shellcode because we want the target program to function in a manner other than what was intended by the designer. One way to manipulate the program is to force it to make a system call or syscall. Syscalls are an extremely powerful set of functions that will allow you to access operating system– specific functions such as getting input, producing output, exiting a process, and executing a binary file. Syscalls allow you to directly access the kernel, which gives you access to lower-level functions like reading and writing files.
More in detail : The concept of Assembly- System calls :http://programmingethicalhackerway.blogspot.in/2015/07/the-concept-of-assembly-system-calls.html
Writing Shellcode for the exit() Syscall: There are basically three ways to write shellcode:
1.writing manually in hex opcode.
2. writing the C code, compile it, and then disassebling it to obtain the assembly instructions and hex opcodes.
3. writing the assembly code and , assemble the program, and then extract the hex opcodes from the binary.
There are various types of shellcode like:
1. Basic Shellcode:It would be nice if we did not have to write our own version of a shell just to upload it to a target computer that probably already has a shell installed. With that in mind, the technique that has become more or less standard typically involves writing assembly code that launches a new shell process on
the target computer and causes that process to take input from and send output to the attacker. The easiest piece of this puzzle to understand turns out to be launching a new shell process, which can be accomplished through use of the execve system call on Unix-like systems and via the CreateProcess function call on Microsoft Windows systems.The more complex aspect is understanding where the new shell process receives its input and where it sends its output.
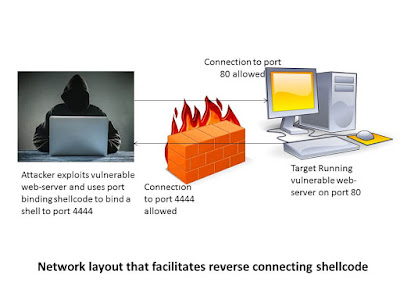
2. Port Binding Shellcode: When attacking a vulnerable networked application, it will not always be the case that simply execing a shell will yield the results we are looking for. If the remote application closes our network connection before our shell has been spawned, we will lose our means to transfer data to and from the shell.One solution to this problem is to use port binding shellcode, often referred to as a “bind shell.”

3. Reverse Shellcode: If a firewall can block our attempts to connect to the listening socket that results from successful use of port binding shellcode.In many cases, firewalls are less restrictive regarding outgoing traffic. Reverse shellcode exploits this fact by reversing the direction in which the second connection is made.Instead of binding to a specific port on the target computer, reverse shellcode initiates a new connection to a specified port on an attacker-controlled computer. Following a successful connection, it duplicates the newly connected socket to stdin, stdout, and stderr before spawning a new command shell process on the target machine.
Kernel Space Shellcode: User space programs are not the only type of code that contains vulnerabilities. Vulnerabilities are also present in operating system kernels and their components, such as device drivers.
Before we start writing exit shellcode, let's understand a C program which is most widely used to test a shellcode.This is an example C code used to test out our codes, there several ways to write this but they works out all the same:
char code[] = "bytecode(like \x31\xdb\xb0\x01x\cd\x80 ) will go here!";
int main(int argc, char **argv)
{
int (*func)(); //func is a function pointer
func = (int (*)()) code; //func points to our code(shellcode)
(int)(*func)(); //execute as function code[]
}
In the main function, the code:
int (*func)();
is a declaration of a function pointer. Actually func is pointer to function returning int.A function pointer is essentially a variable that holds the address of a function. In this case, the type of function that func points to is a one that takes no arguments and returns an int.
The next line:
func = (int (*)()) code;
assigns a function pointer an address to the code[] (which is assembler bytecode, the instructions your CPU executes). Here (int (*)()) is a cast to a function pointer that takes no arguments and returns an int. This is so the compiler won't complain about assigning what is essentially a char* to the function pointer func.
The last line:
(int)(*func)();
calls the function by its address (assembler instructions) with no arguments passed,because () is specified.
Here the result is cast to an int and this cast is not necessary.So the last line
(int)(*func)();
could be replaced with
(*func)();
Note:
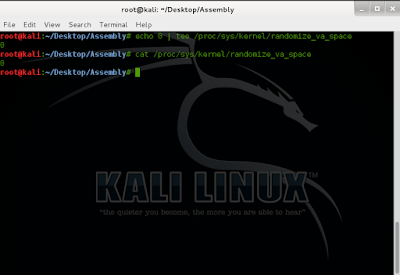
1. Address Space Layout Randomization is a defense feature to make buffer overflows more difficult, and Kali Linux uses it by default. Fortunately, it's easy to temporarily disable ASLR in Kali Linux.
In a Terminal, execute these commands: :
root@kali:~/Desktop/Assembly# echo 0 | tee /proc/sys/kernel/randomize_va_space
0
root@kali:~/Desktop/Assembly# cat /proc/sys/kernel/randomize_va_space
0
2.To compile the code without modern protections against stack overflows :
root@kali:~/Desktop/Assembly# gcc test.c -o test -ggdb -fno-stack-protector -z execstack
Essentially, you now have all the pieces you need to make exit() shellcode.Our first step will be to use the assembly code from previous tutorial "exit.asm" code example to write a shellcode.The assembly code is :
global _start
section .text
_start:
mov ebx,0
mov eax, 1
int 0x80
If this code is not clear , check here:http://programmingethicalhackerway.blogspot.in/2015/07/a-simple-exit-assembly-program.html
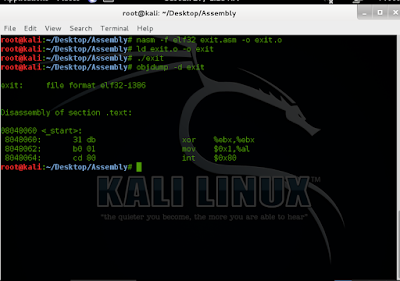
Now To get the opcodes, we will first assemble the code with nasm andthen use the GNU linker to link object files;then disassemble the freshly built binary with objdump:
root@kali:~/Desktop/Assembly# nasm -f elf32 exit.asm -o exit.o
root@kali:~/Desktop/Assembly# ld exit.o -o exit
root@kali:~/Desktop/Assembly# ./exit
root@kali:~/Desktop/Assembly# objdump -d exit
exit: file format elf32-i386
Disassembly of section .text:
08048060 <_start>:
8048060: bb 00 00 00 00 mov $0x0,%ebx
8048065: b8 01 00 00 00 mov $0x1,%eax
804806a: cd 80 int $0x80
root@kali:~/Desktop/Assembly#

You can see the assembly instructions on the far right. To the left is our opcode.The second column contains the opcodes we need. All you need to do is place the opcode into a character array and whip up a little C to execute the string.Therefore, we can write our first shellcode and test it with a very simple C program(Discussed above):
char shellcode[] = "\xbb\x00\x00\x00\x00"
"\xb8\x01\x00\x00\x00"
"\xcd\x80";
int main(int argc, char **argv)
{
int (*func)();
func = (int (*)()) code;
(int)(*func)();
}
Now, compile the program and test the shellcode:
root@kali:~/Desktop/Assembly# gcc test.c -o test -ggdb -fno-stack-protector -z execstack
root@kali:~/Desktop/Assembly# ./test
root@kali:~/Desktop/Assembly#
It looks like the program exited normally. Unfortunately, looking at the shellcode, we can notice a little problem: it contains a lot of null bytes and, since the shellcode is often written into a string buffer, those bytes will be treated as string terminators by the application and the attack will fail.
There are two ways to get around this problem:
1.writing instructions that don't contain null bytes (not always possible),
2. writing a self-modifying shellcode (without null bytes) which will write the necessary null bytes (e.g. string terminators) at run-time.
Here we will apply the first method.First, the first instruction:
mov $0x0,%ebx
can be replaced by the more common :
xor ebx, ebx
Instead of using the mov instruction to set the value of EBX to 0,use the Exclusive OR (xor) instruction.If you remember assembly, the Exclusive OR (xor) instruction will return zero if both operands are equal. This means that if we use the Exclusive OR instruction on two operands that we know are equal, we can get the value of 0 without having to use a value of 0 in an instruction.
The second instruction:
mov $0x1,%eax
instead, contained all those zeroes because we were using a 32 bit register (EAX), thus making 0x01 become 0x01000000 (bytes are in reverse order because Intel processors are little endian).We can get around this problem if we remember that each 32-bit register is broken up into two 16-bit “areas”; the first-16 bit area can be accessed with the AX register. Additionally, the 16-bit AX register can be broken down further into the AL and AH registers. If you want only the first 8 bits, you can use the AL register.
Our binary value of 1 will take up only 8 bits, so we can fit our value into this register and avoid EAX
getting filled up with nulls. Therefore, we can solve this problem simply using an 8 bit register (AL) instead of a 32 bit register:
mov al,1
Now we should have taken care of all the nulls. Let’s verify that we have by writing our new assembly instructions and seeing if we have any null opcodes.Now our assembly code looks like:
global _start
section .text
_start:
xor ebx,ebx ;zero out ebx
mov al, 1 ;exit is syscall 1
int 0x80
Take the following steps to compile and extract the byte code.
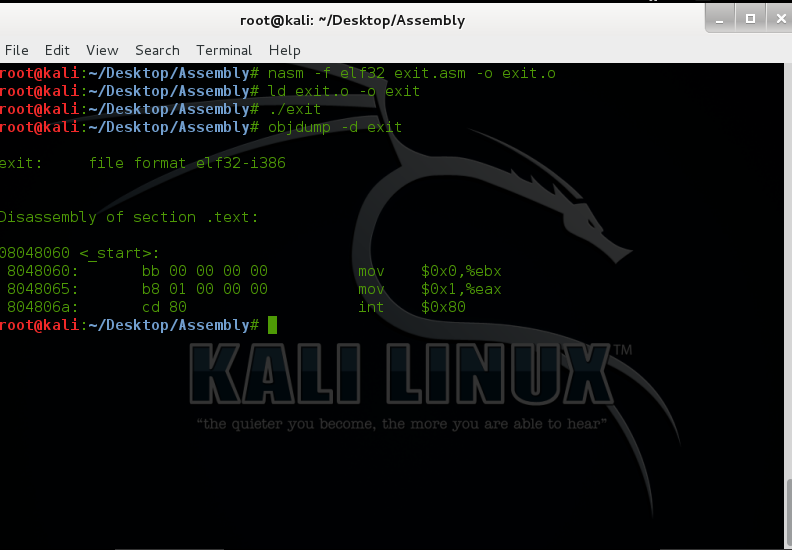
root@kali:~/Desktop/Assembly# nasm -f elf32 exit.asm -o exit.o
root@kali:~/Desktop/Assembly# ld exit.o -o exit
root@kali:~/Desktop/Assembly# ./exit
root@kali:~/Desktop/Assembly# objdump -d exit
exit: file format elf32-i386
Disassembly of section .text:
08048060 <_start>:
8048060: 31 db xor %ebx,%ebx
8048062: b0 01 mov $0x1,%al
8048064: cd 80 int $0x80
The bytes we need are 31 db b0 01 cd 80.As you can see, doesn't contain any null bytes!All our null opcodes have been removed, and we have significantly reduced the size of our shellcode. Now you have fully working, and more importantly, injectable shellcode.
Now test the new shellcode:
char shellcode[] = "\x31\xdb\xb0\x01"
"\xcd\x80";
int main(int argc, char **argv)
{
int (*func)();
func = (int (*)()) code;
(int)(*func)();
}
Once again, to make the shellcode work in real-world applications, we will need to remove all those null bytes!
Ideas for writing small shellcode : Here i will share some useful ideas for constructing shellcode that is as small as possible.
1. Use small instructions.
2. Use instructions with multiple effects.
3. Bend Windows API rules.
4. Don’t think like a programmer.
5. Consider using encoding or compression.
Prerequisites: x86 Assembly language(Strictly Recommended).
2. C programming language.
Caution:The shellcodes can be used in most exploits without a problem.However, these codes may cause serious damage to your computer and should therefor only be used against TEST systems that have NO network connectivity! Imagine what happens if you run the backdoor on you system and forget about it ?
What is shellcode?
The shellcode is literally a "code" that returns a remote (or local) shell when executed. Shellcode can be seen as a list of instructions that has been developed in a manner that allows it to be injected in an application during runtime.The term “shellcode” (or “shell code”) derives from the fact that in many cases, malicious users utilize code that provides them with either shell access to a remote computer on which they do not possess an account or, alternatively, access to a shell with higher privileges on a computer on which they do have an account. In the optimal case, such a shell might provide root- or administrator-level access to a vulnerable system.
Understanding shellcode and eventually writing your own is, for many reasons, an essential skill. First and foremost, in order to determine that a vulnerability is indeed exploitable, you must first exploit it. Second, software vendors will often release a notice of a vulnerability but not provide an exploit. In these cases you may have to write your own shellcode if you want to create an exploit in order to test the bug on your own systems. Unfortunately, for many hackers the shellcode story stops at copying and pasting bytes. These hackers are just scratching the surface of what’s possible.Custom shellcode gives you absolute control over the exploited program. Perhaps you want your shellcode to add an admin account to /etc/passwd or to automatically remove lines from log files. Once you know how to write your own shellcode, your exploits are limited only by your imagination. In addition, writing shellcode develops assembly language skills and employs a number of hacking techniques worth knowing.
Understanding System Calls: As we have already discussed,System calls are APIs for the interface between user space and kernel space.We write shellcode because we want the target program to function in a manner other than what was intended by the designer. One way to manipulate the program is to force it to make a system call or syscall. Syscalls are an extremely powerful set of functions that will allow you to access operating system– specific functions such as getting input, producing output, exiting a process, and executing a binary file. Syscalls allow you to directly access the kernel, which gives you access to lower-level functions like reading and writing files.
More in detail : The concept of Assembly- System calls :http://programmingethicalhackerway.blogspot.in/2015/07/the-concept-of-assembly-system-calls.html
Writing Shellcode for the exit() Syscall: There are basically three ways to write shellcode:
1.writing manually in hex opcode.
2. writing the C code, compile it, and then disassebling it to obtain the assembly instructions and hex opcodes.
3. writing the assembly code and , assemble the program, and then extract the hex opcodes from the binary.
There are various types of shellcode like:
1. Basic Shellcode:It would be nice if we did not have to write our own version of a shell just to upload it to a target computer that probably already has a shell installed. With that in mind, the technique that has become more or less standard typically involves writing assembly code that launches a new shell process on
the target computer and causes that process to take input from and send output to the attacker. The easiest piece of this puzzle to understand turns out to be launching a new shell process, which can be accomplished through use of the execve system call on Unix-like systems and via the CreateProcess function call on Microsoft Windows systems.The more complex aspect is understanding where the new shell process receives its input and where it sends its output.
2. Port Binding Shellcode: When attacking a vulnerable networked application, it will not always be the case that simply execing a shell will yield the results we are looking for. If the remote application closes our network connection before our shell has been spawned, we will lose our means to transfer data to and from the shell.One solution to this problem is to use port binding shellcode, often referred to as a “bind shell.”

3. Reverse Shellcode: If a firewall can block our attempts to connect to the listening socket that results from successful use of port binding shellcode.In many cases, firewalls are less restrictive regarding outgoing traffic. Reverse shellcode exploits this fact by reversing the direction in which the second connection is made.Instead of binding to a specific port on the target computer, reverse shellcode initiates a new connection to a specified port on an attacker-controlled computer. Following a successful connection, it duplicates the newly connected socket to stdin, stdout, and stderr before spawning a new command shell process on the target machine.

Kernel Space Shellcode: User space programs are not the only type of code that contains vulnerabilities. Vulnerabilities are also present in operating system kernels and their components, such as device drivers.
Before we start writing exit shellcode, let's understand a C program which is most widely used to test a shellcode.This is an example C code used to test out our codes, there several ways to write this but they works out all the same:
char code[] = "bytecode(like \x31\xdb\xb0\x01x\cd\x80 ) will go here!";
int main(int argc, char **argv)
{
int (*func)(); //func is a function pointer
func = (int (*)()) code; //func points to our code(shellcode)
(int)(*func)(); //execute as function code[]
}
In the main function, the code:
int (*func)();
is a declaration of a function pointer. Actually func is pointer to function returning int.A function pointer is essentially a variable that holds the address of a function. In this case, the type of function that func points to is a one that takes no arguments and returns an int.
The next line:
func = (int (*)()) code;
assigns a function pointer an address to the code[] (which is assembler bytecode, the instructions your CPU executes). Here (int (*)()) is a cast to a function pointer that takes no arguments and returns an int. This is so the compiler won't complain about assigning what is essentially a char* to the function pointer func.
The last line:
(int)(*func)();
calls the function by its address (assembler instructions) with no arguments passed,because () is specified.
Here the result is cast to an int and this cast is not necessary.So the last line
(int)(*func)();
could be replaced with
(*func)();
Note:
1. Address Space Layout Randomization is a defense feature to make buffer overflows more difficult, and Kali Linux uses it by default. Fortunately, it's easy to temporarily disable ASLR in Kali Linux.
In a Terminal, execute these commands: :
root@kali:~/Desktop/Assembly# echo 0 | tee /proc/sys/kernel/randomize_va_space
0
root@kali:~/Desktop/Assembly# cat /proc/sys/kernel/randomize_va_space
0

2.To compile the code without modern protections against stack overflows :
root@kali:~/Desktop/Assembly# gcc test.c -o test -ggdb -fno-stack-protector -z execstack
Essentially, you now have all the pieces you need to make exit() shellcode.Our first step will be to use the assembly code from previous tutorial "exit.asm" code example to write a shellcode.The assembly code is :
global _start
section .text
_start:
mov ebx,0
mov eax, 1
int 0x80
If this code is not clear , check here:http://programmingethicalhackerway.blogspot.in/2015/07/a-simple-exit-assembly-program.html
Now To get the opcodes, we will first assemble the code with nasm andthen use the GNU linker to link object files;then disassemble the freshly built binary with objdump:
root@kali:~/Desktop/Assembly# nasm -f elf32 exit.asm -o exit.o
root@kali:~/Desktop/Assembly# ld exit.o -o exit
root@kali:~/Desktop/Assembly# ./exit
root@kali:~/Desktop/Assembly# objdump -d exit
exit: file format elf32-i386
Disassembly of section .text:
08048060 <_start>:
8048060: bb 00 00 00 00 mov $0x0,%ebx
8048065: b8 01 00 00 00 mov $0x1,%eax
804806a: cd 80 int $0x80
root@kali:~/Desktop/Assembly#
You can see the assembly instructions on the far right. To the left is our opcode.The second column contains the opcodes we need. All you need to do is place the opcode into a character array and whip up a little C to execute the string.Therefore, we can write our first shellcode and test it with a very simple C program(Discussed above):
char shellcode[] = "\xbb\x00\x00\x00\x00"
"\xb8\x01\x00\x00\x00"
"\xcd\x80";
int main(int argc, char **argv)
{
int (*func)();
func = (int (*)()) code;
(int)(*func)();
}
Now, compile the program and test the shellcode:
root@kali:~/Desktop/Assembly# gcc test.c -o test -ggdb -fno-stack-protector -z execstack
root@kali:~/Desktop/Assembly# ./test
root@kali:~/Desktop/Assembly#
It looks like the program exited normally. Unfortunately, looking at the shellcode, we can notice a little problem: it contains a lot of null bytes and, since the shellcode is often written into a string buffer, those bytes will be treated as string terminators by the application and the attack will fail.
There are two ways to get around this problem:
1.writing instructions that don't contain null bytes (not always possible),
2. writing a self-modifying shellcode (without null bytes) which will write the necessary null bytes (e.g. string terminators) at run-time.
Here we will apply the first method.First, the first instruction:
mov $0x0,%ebx
can be replaced by the more common :
xor ebx, ebx
Instead of using the mov instruction to set the value of EBX to 0,use the Exclusive OR (xor) instruction.If you remember assembly, the Exclusive OR (xor) instruction will return zero if both operands are equal. This means that if we use the Exclusive OR instruction on two operands that we know are equal, we can get the value of 0 without having to use a value of 0 in an instruction.
The second instruction:
mov $0x1,%eax
instead, contained all those zeroes because we were using a 32 bit register (EAX), thus making 0x01 become 0x01000000 (bytes are in reverse order because Intel processors are little endian).We can get around this problem if we remember that each 32-bit register is broken up into two 16-bit “areas”; the first-16 bit area can be accessed with the AX register. Additionally, the 16-bit AX register can be broken down further into the AL and AH registers. If you want only the first 8 bits, you can use the AL register.
Our binary value of 1 will take up only 8 bits, so we can fit our value into this register and avoid EAX
getting filled up with nulls. Therefore, we can solve this problem simply using an 8 bit register (AL) instead of a 32 bit register:
mov al,1
Now we should have taken care of all the nulls. Let’s verify that we have by writing our new assembly instructions and seeing if we have any null opcodes.Now our assembly code looks like:
global _start
section .text
_start:
xor ebx,ebx ;zero out ebx
mov al, 1 ;exit is syscall 1
int 0x80
Take the following steps to compile and extract the byte code.
root@kali:~/Desktop/Assembly# nasm -f elf32 exit.asm -o exit.o
root@kali:~/Desktop/Assembly# ld exit.o -o exit
root@kali:~/Desktop/Assembly# ./exit
root@kali:~/Desktop/Assembly# objdump -d exit
exit: file format elf32-i386
Disassembly of section .text:
08048060 <_start>:
8048060: 31 db xor %ebx,%ebx
8048062: b0 01 mov $0x1,%al
8048064: cd 80 int $0x80

The bytes we need are 31 db b0 01 cd 80.As you can see, doesn't contain any null bytes!All our null opcodes have been removed, and we have significantly reduced the size of our shellcode. Now you have fully working, and more importantly, injectable shellcode.
Now test the new shellcode:
char shellcode[] = "\x31\xdb\xb0\x01"
"\xcd\x80";
int main(int argc, char **argv)
{
int (*func)();
func = (int (*)()) code;
(int)(*func)();
}
Once again, to make the shellcode work in real-world applications, we will need to remove all those null bytes!
Ideas for writing small shellcode : Here i will share some useful ideas for constructing shellcode that is as small as possible.
1. Use small instructions.
2. Use instructions with multiple effects.
3. Bend Windows API rules.
4. Don’t think like a programmer.
5. Consider using encoding or compression.
If you like this post or have any question, please feel free to comment!
No comments:
Post a Comment